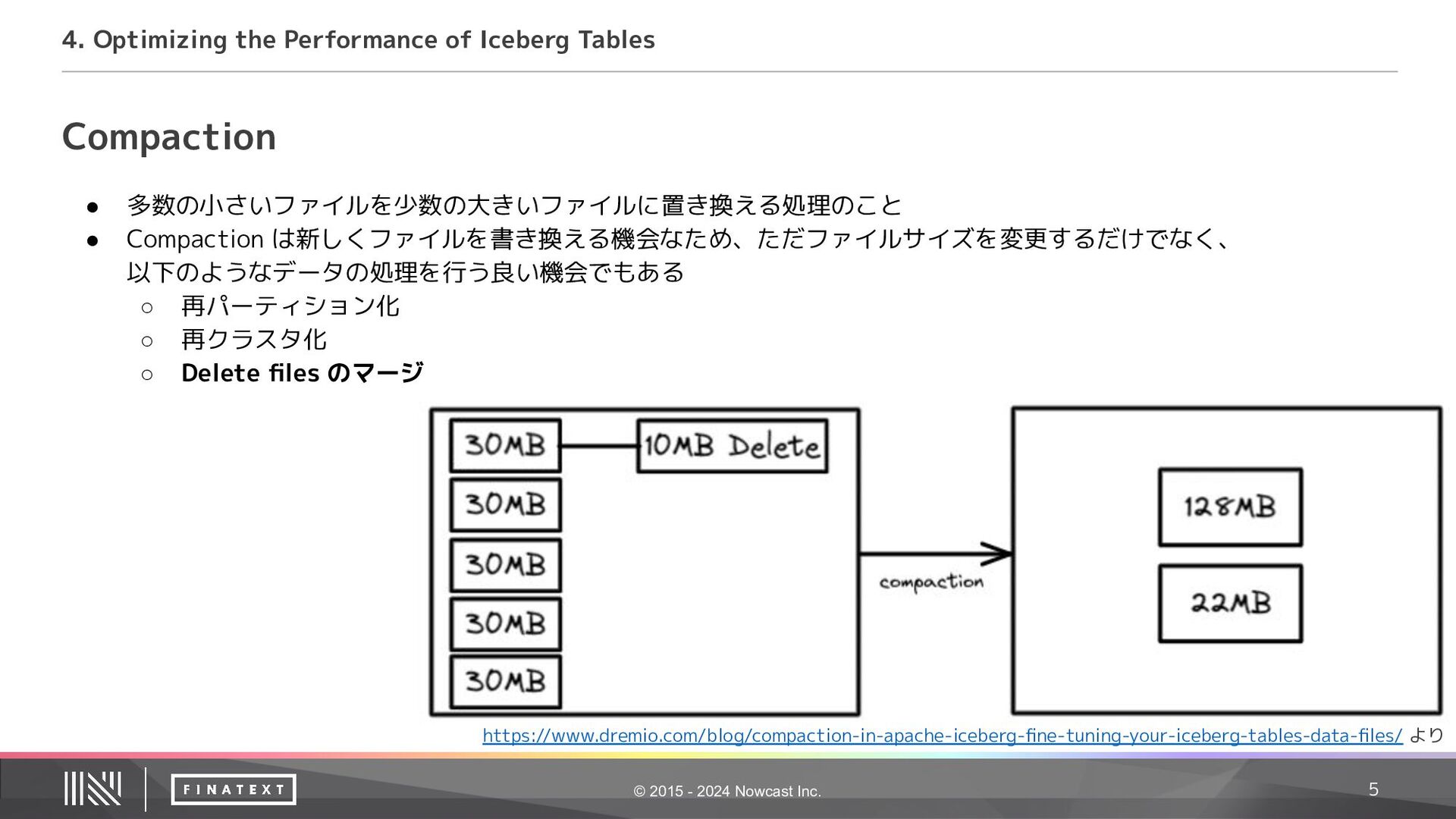
Performance of Iceberg Tables • クラスタリングのポイントは似たデータを近い場所(同じファイル)に配置しておくこと • 相関がないような複数のカラムで普通にソートしても、最初のカラム以外は散らばってしまう • 2つのカラムでクラスタリングすること考えた時に、 普通のソートと z order によるソートを比べると、 二次元平面で見た時に z order によるソートの方が 平面内で近い点を順番に通ることがわかる • これにより、2つのカラムでフィルタリングしても どちらでも効率よく pruning ができるようになる z order での sort https://medium.com/@nishant.chandra/z-order-indexing-for-efficient-queries-in-data-lake-48eceaeb2320 より
Performance of Iceberg Tables • クラスタリングのポイントは似たデータを近い場所(同じファイル)に配置しておくこと • 相関がないような複数のカラムで普通にソートしても、最初のカラム以外は散らばってしまう • 2つのカラムでクラスタリングすること考えた時に、 普通のソートと z order によるソートを比べると、 二次元平面で見た時に z order によるソートの方が 平面内で近い点を順番に通ることがわかる • これにより、2つのカラムでフィルタリングしても どちらでも効率よく pruning ができるようになる z order での sort https://www.waitingforcode.com/delta-lake/table-file-formats-z-order-compaction-delta-lake/read より
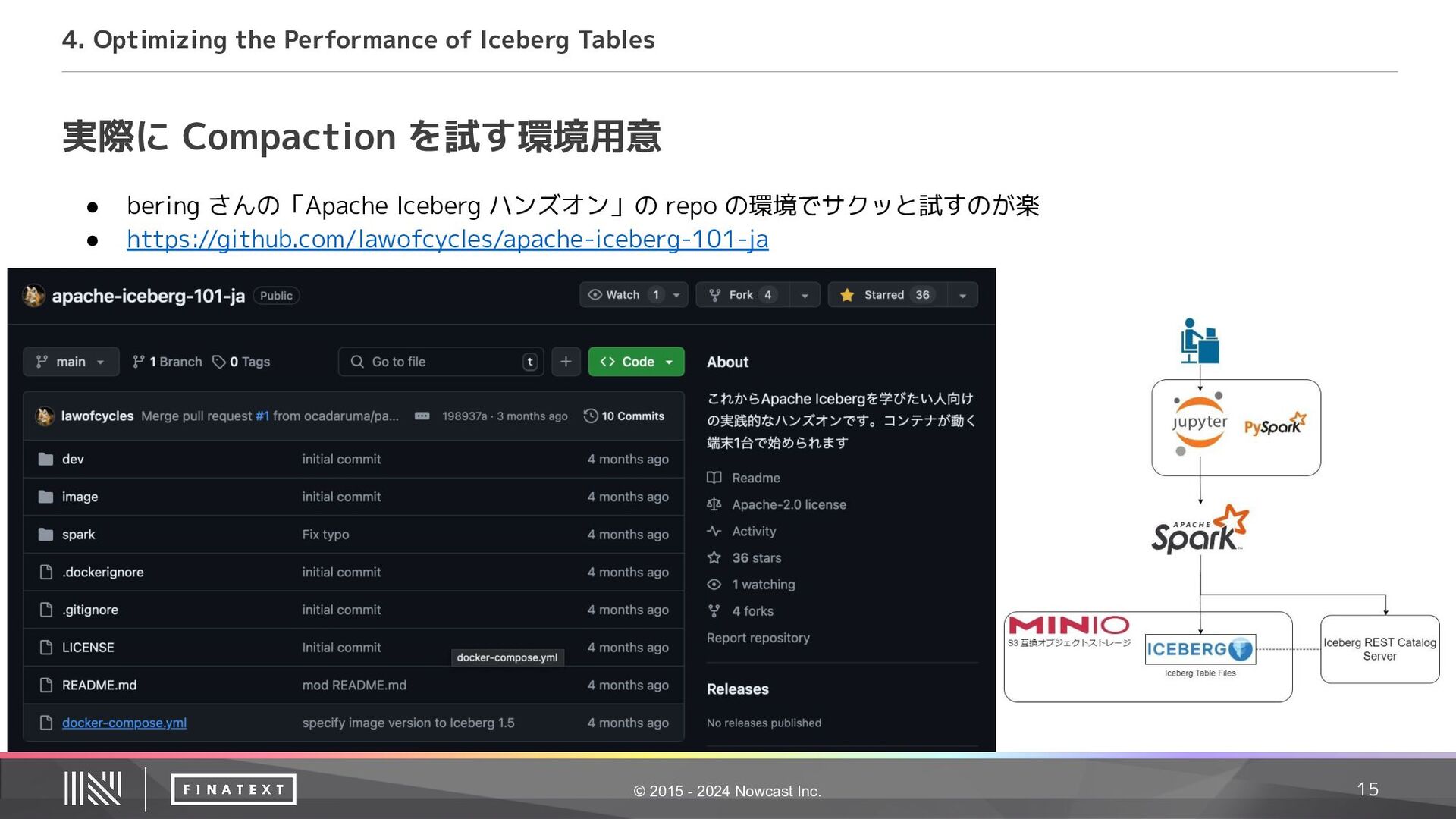
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}