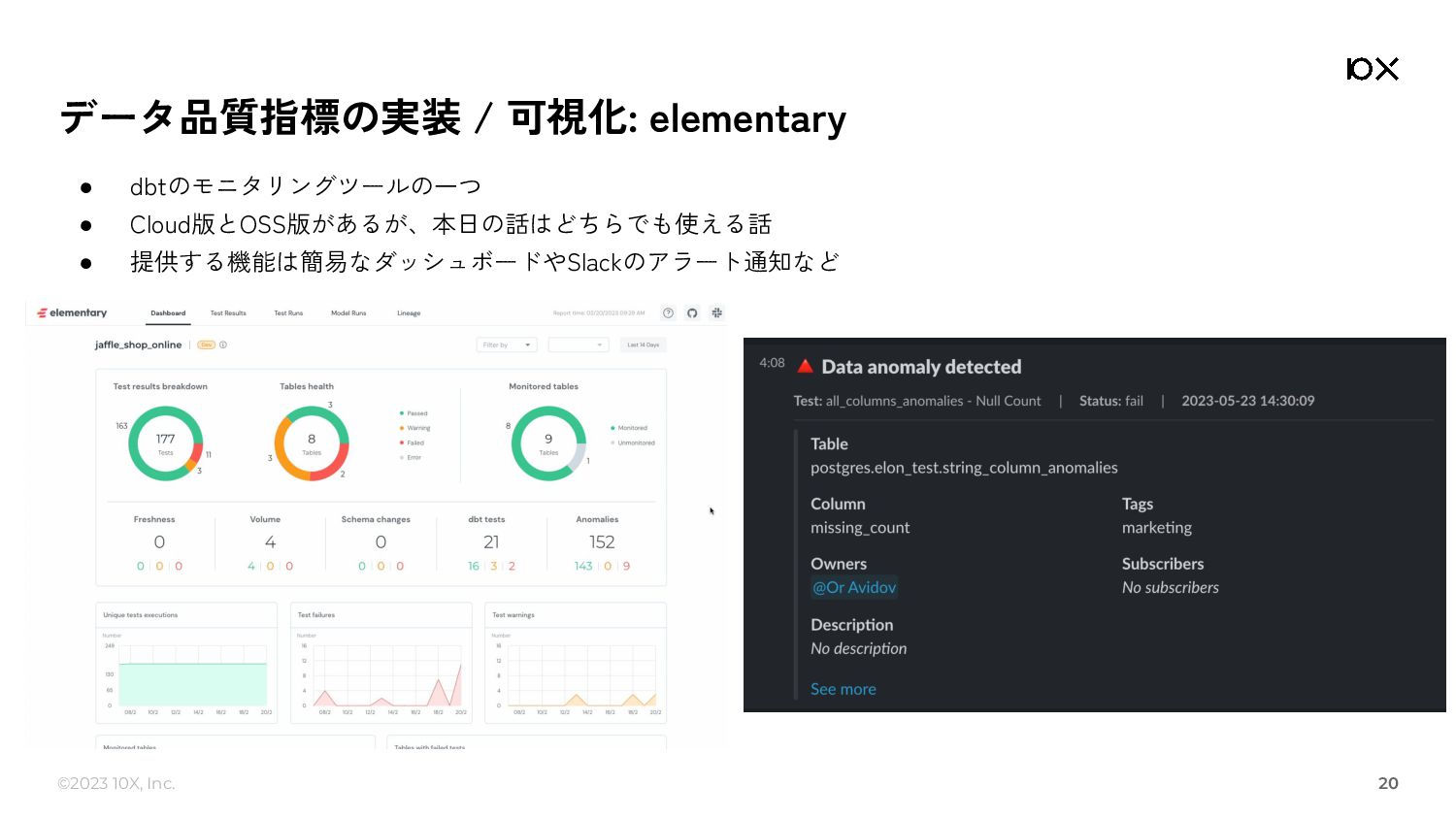
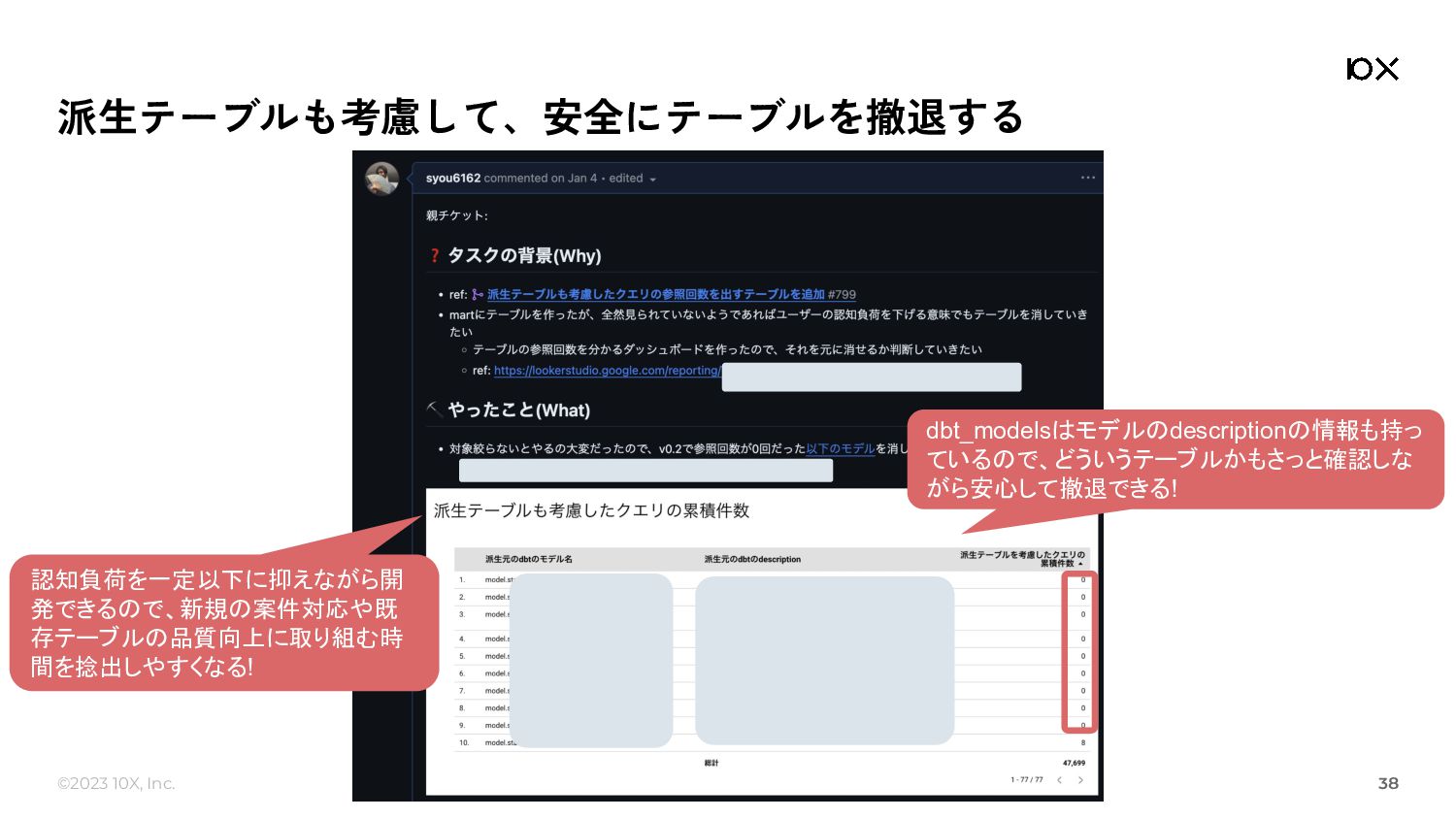
◦ いつどういう{model, test, seed, snapshot}が実行され、どうなったか(status)が蓄積される ◦ これ単独だと、INFORMATION_SCHEMA.JOBSができることとほとんど変わらないように見える ▪ しかし、後述するdbt_modelsやdbt_testsやdbt_sourcesなどと組み合わせると非常に強力 ▪ JOINして組み合わせるためのキーがunique_id • dbt_models: dbtのmodel(table / view / ephemeralなど)に関するメタデータを保持しているテーブル 26 カラム名 詳細 database_name プロジェクト名 schema_name データセット名 tags タグの配列が文字列で入っているので、使う際はバラす必要がある depends_on_nodes 依存(ref)しているモデルが配列として入っている description 問題あるモデルの一覧を出したときに「このモデル、どういう目的のものだっけ」をさっと見れる original_path モデルの定義元のファイルパス。モデルの一覧を出したときに「このモデルの詳細調べたいな」をさっと調査できる 情報量としては各種yamlファイルや manifest.jsonとほぼ同じ。 しかし、SQLのみで料理できるようになっ ている、ということが重要!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}